ChronoFlow-Policy unifies past, current, and future interaction flow. The policy reasons over sparse 3D object and gripper keypoints, then uses ChronoFlow as a co-training target for diffusion-based action generation.
ChronoFlow-Policy demonstrations across simulated and real-world manipulation tasks.
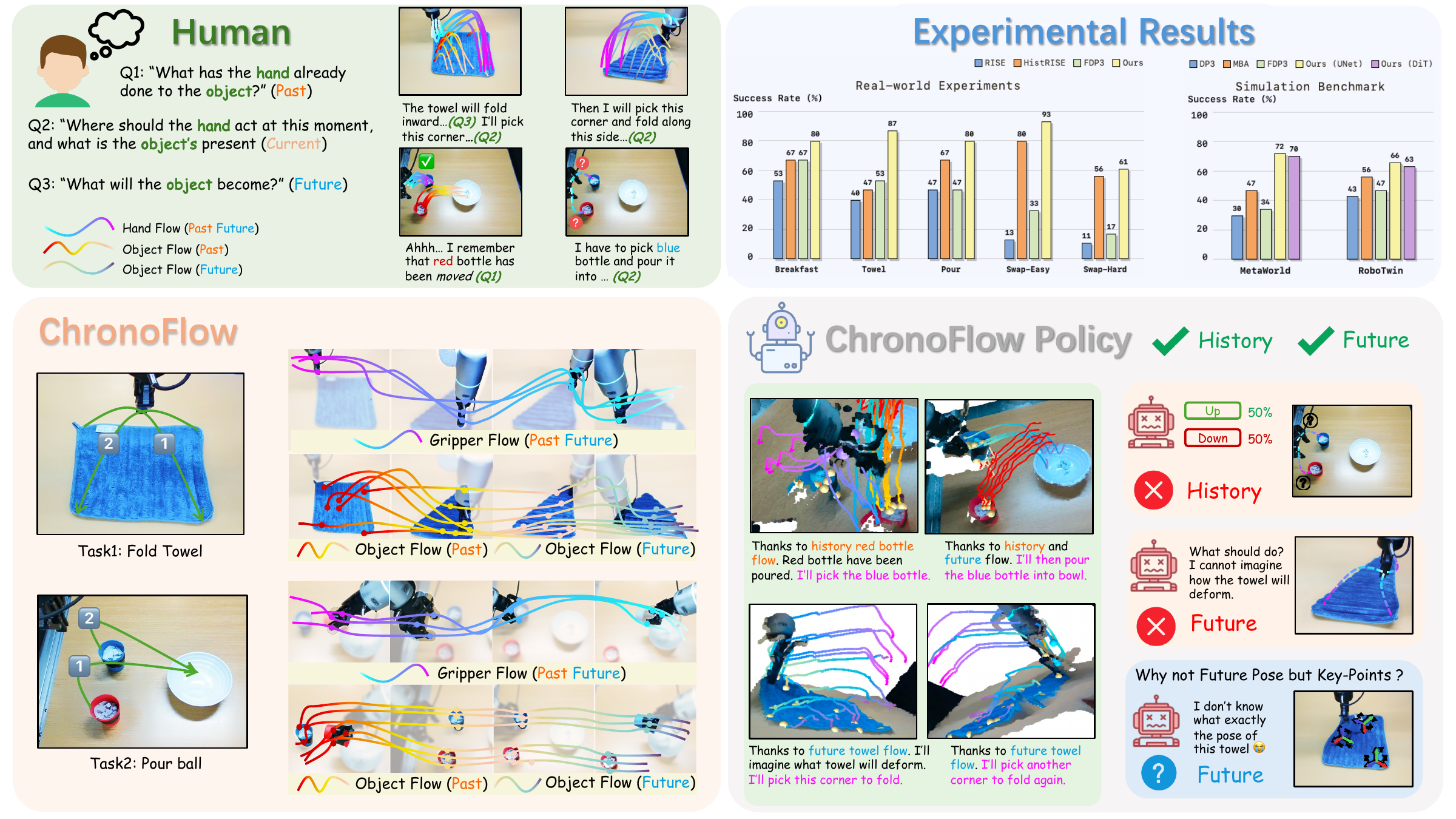
Visual signals play a crucial role in policy learning by enabling models to capture object motion and interaction dynamics. Just as humans reason about actions using both past experience and anticipated outcomes, effective policies should integrate past interactions with future predictions.
We introduce ChronoFlow, a temporally unified representation that captures past, current, and future interaction dynamics through sparse 3D keypoints of both objects and the gripper. Based on this representation, ChronoFlow-Policy jointly learns ChronoFlow and action sequences through a diffusion co-training objective.
Experiments on 14 simulated tasks and 5 real-world manipulation tasks show consistent gains over strong diffusion-policy baselines, especially in long-horizon, deformable, and non-Markovian manipulation scenarios.
Historical object-gripper keypoint flows provide memory of previous interactions, which is critical for non-Markovian tasks such as Swap-Easy and Swap-Hard.
A single RGB-D observation is encoded as a 3D point-cloud feature, grounding the policy in the current manipulation state.
Future ChronoFlow prediction provides interaction foresight, letting actions be decoded from predicted object and gripper motion rather than action labels alone.
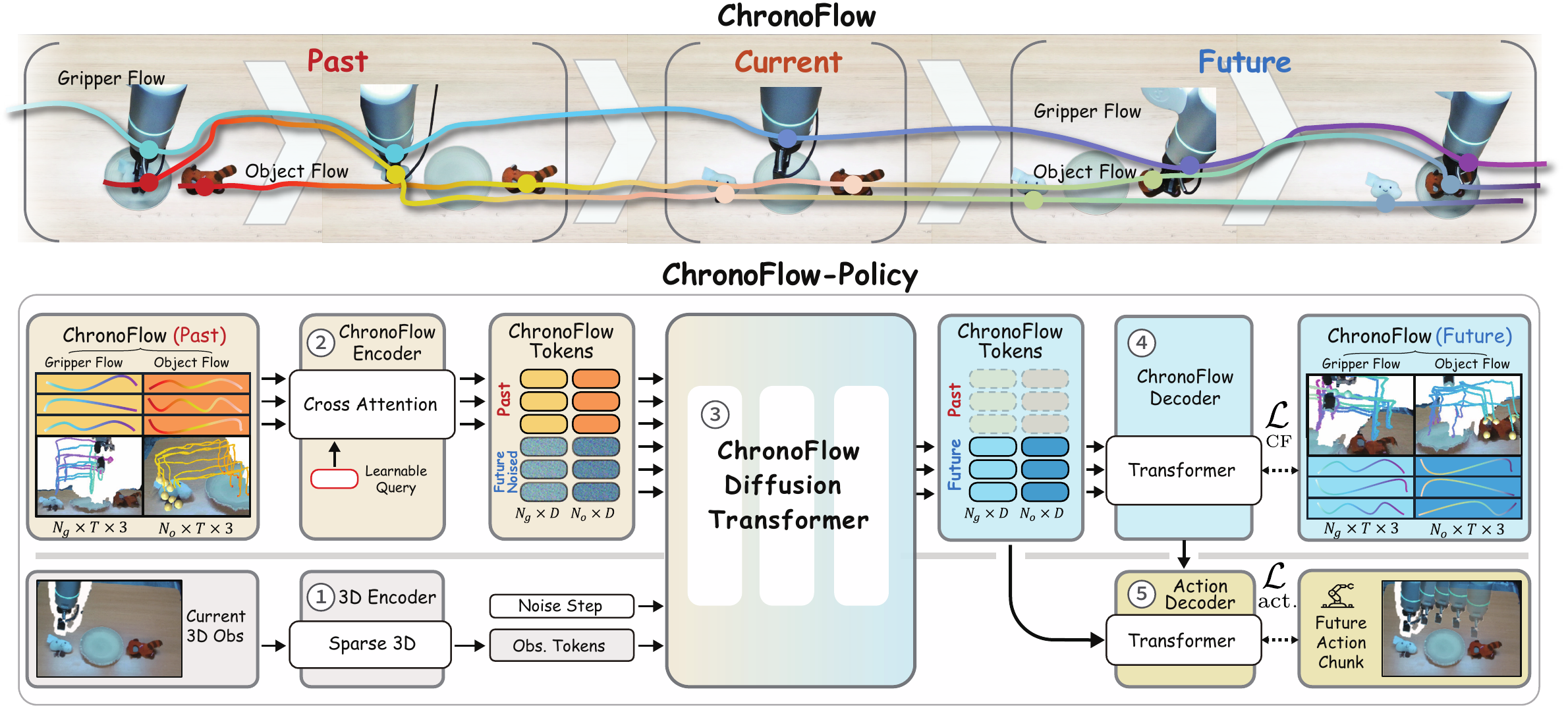
Overview of ChronoFlow-Policy. ChronoFlow represents past-current-future object-gripper keypoint flows. A ChronoFlow encoder, diffusion backbone, ChronoFlow decoder, and action decoder jointly learn interaction trajectories and robot actions.
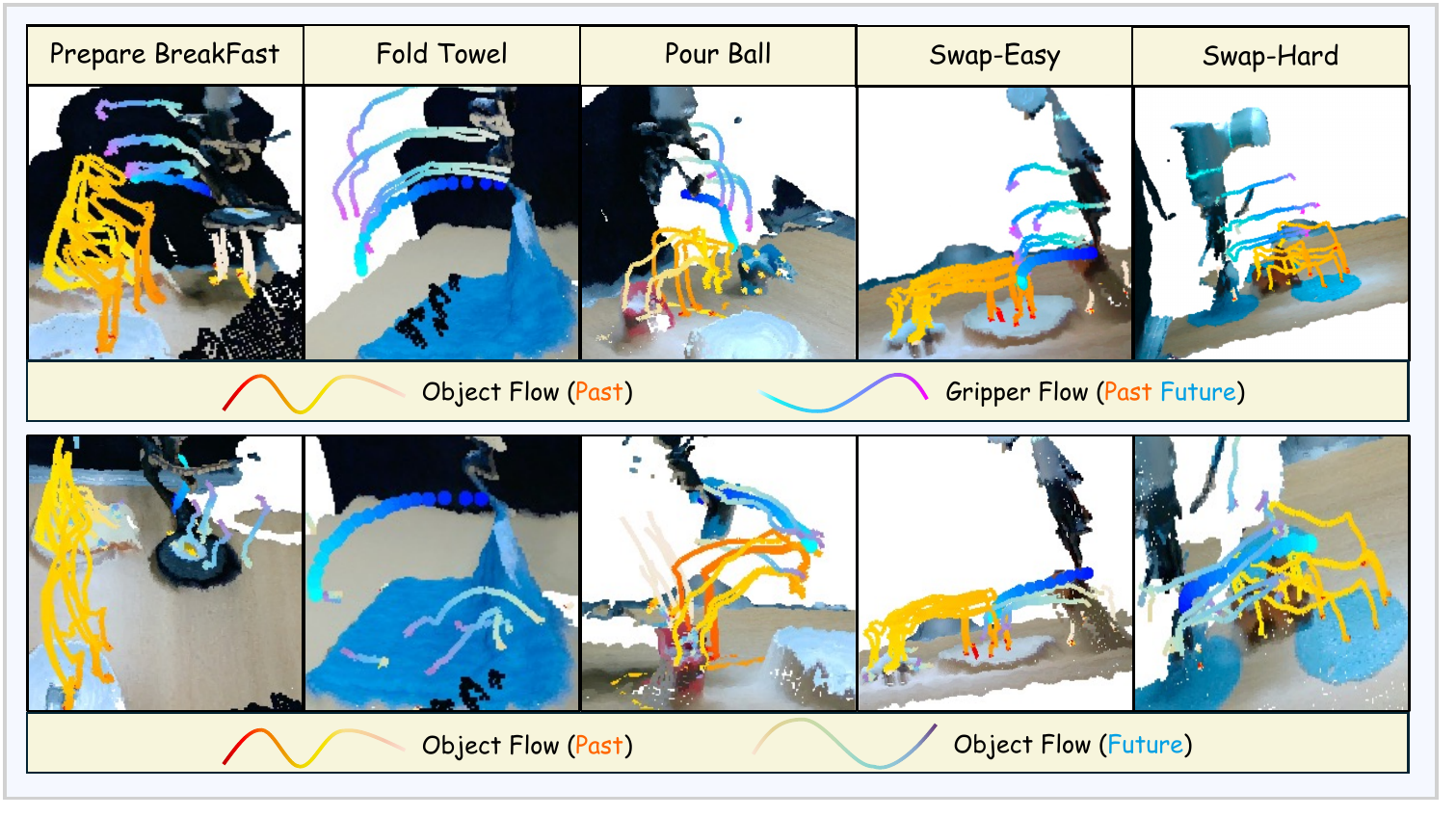
ChronoFlow tracks sparse 3D keypoints on both the gripper and task-relevant objects, forming compact interaction trajectories instead of dense scene-level motion.
Learnable interaction queries use cross-attention to encode historical ChronoFlow and noisy future ChronoFlow into compact object and gripper tokens.
The diffusion backbone denoises ChronoFlow tokens while conditioned on the current 3D observation, shaping the latent state into an interaction model.
A lightweight transformer decoder predicts actions from partially denoised ChronoFlow tokens and approximate future interaction trajectories.
During deployment, historical ChronoFlow trajectories are obtained asynchronously with TAPIP3D. The policy starts from Gaussian noise, iteratively denoises future ChronoFlow, and decodes both future keypoint trajectories and a horizon of robot actions. The asynchronous tracker keeps the real-world policy running at 5.82 Hz, compared with 0.93 Hz for synchronous tracking.
Supervision, history, future modeling, and gains reported in the paper.
| Method | Supervision | History | Future | Gain (Sim. / Real) |
|---|---|---|---|---|
| DP3 / RISE | Action-only | × | × | - / - |
| HistDP3 / HistRISE | Action-only | Yes | × | +2.2 / +25.8 |
| 3D-FDP | Dense scene flow | × | Yes | +4.0 / +6.9 |
| MBA | Object pose trajectory | × | Yes | +15.0 / +20.0 |
| CFP w/o past | ChronoFlow | × | Yes | +32.5 / +11.8 |
| CFP | ChronoFlow | Yes | Yes | +32.5 / +35.3 |
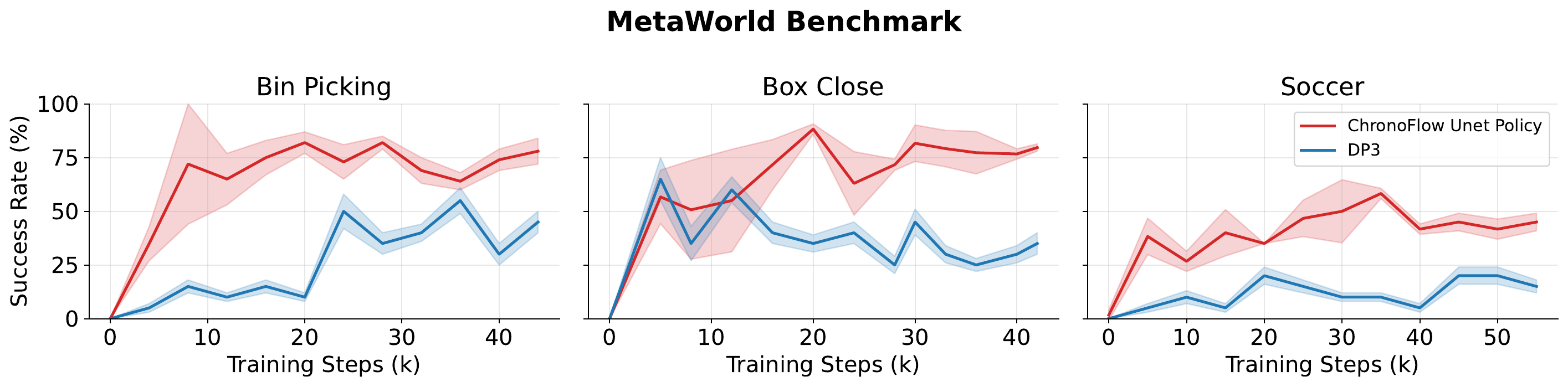
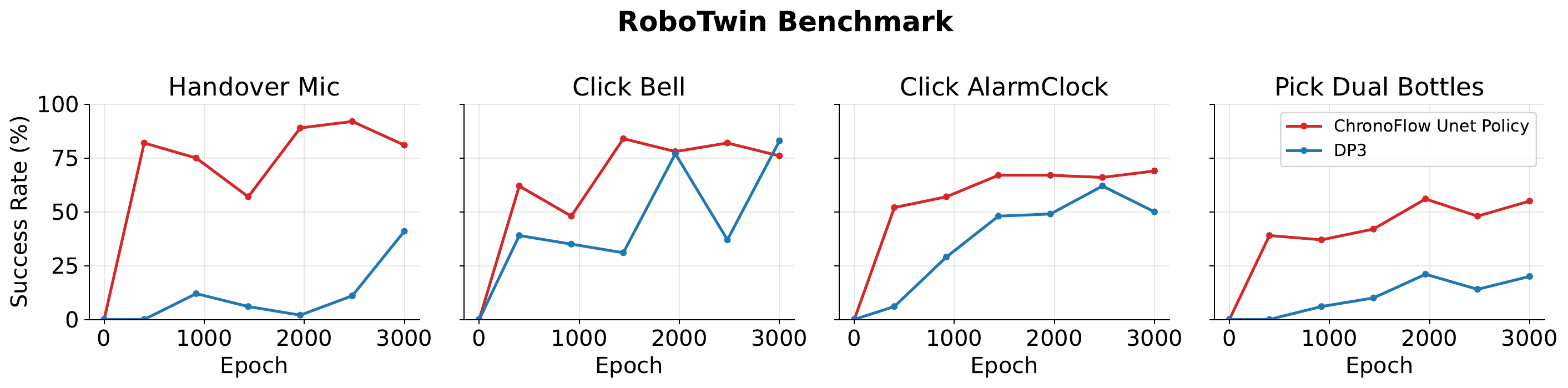
Success rates (%) on MetaWorld and RoboTwin 2.0. Best results are bold and second-best results are underlined.
| Method | MetaWorld Avg. | RoboTwin Avg. |
|---|---|---|
| DP3 | 30 | 43 |
| 3D-FDP | 34 | 47 |
| MBA | 47 | 56 |
| CFP (Unet) | 72 | 66 |
| CFP (DiT) | 70 | 63 |
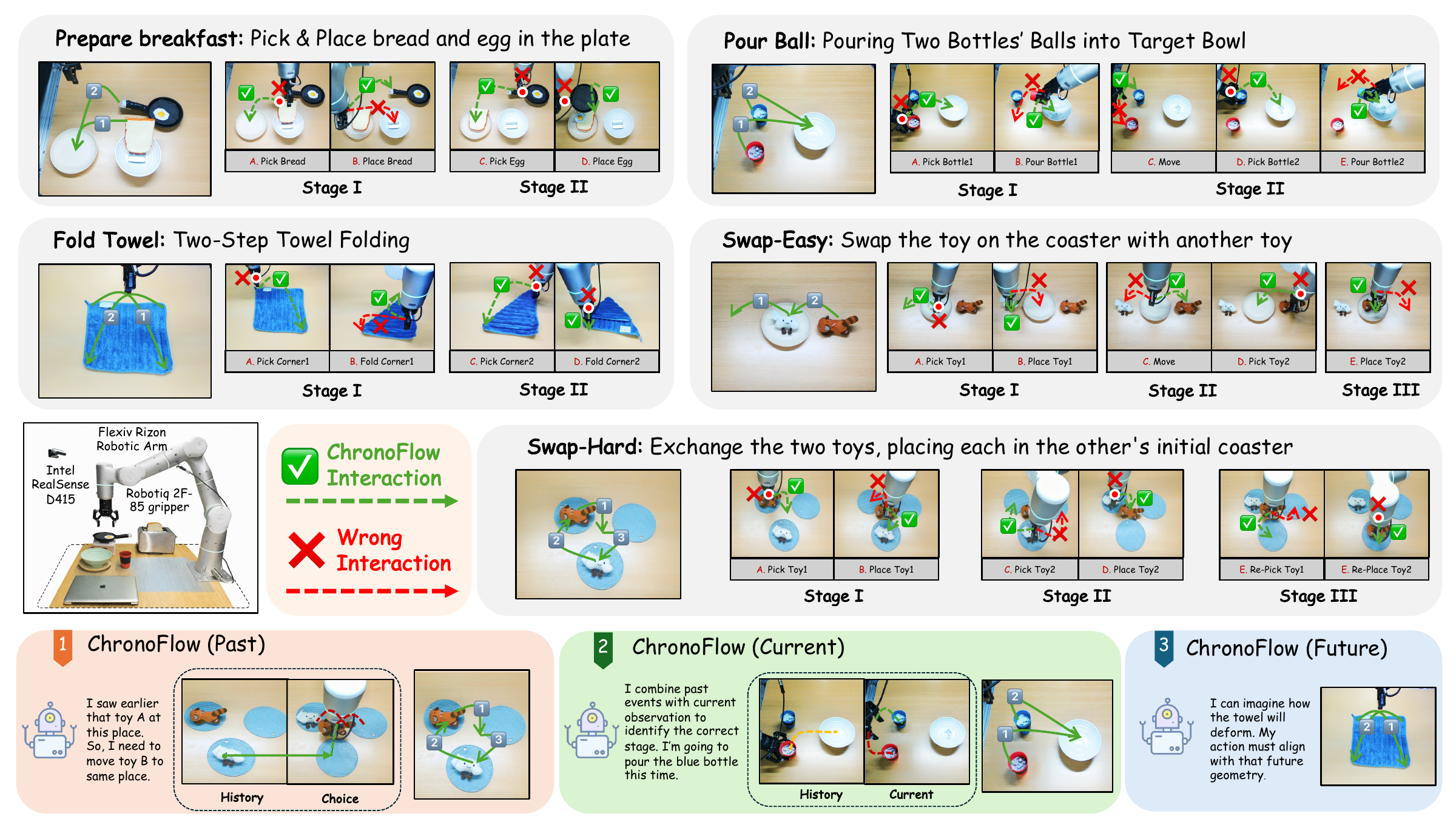
Real-world manipulation tasks. The benchmark covers long-horizon execution, soft-object folding, and non-Markovian object swaps where the correct action depends on past interactions.
| Task | Breakfast | Towel | Pour | Swap-Easy | Swap-Hard | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Stage | I | II | I | II | I | II | I | II | III | I | II | III |
| RISE | 73 | 53 | 80 | 40 | 80 | 47 | 87 | 27 | 13 | 89 | 17 | 11 |
| 3D-FDP | 73 | 67 | 87 | 53 | 73 | 47 | 93 | 40 | 33 | 83 | 33 | 17 |
| HistRISE | 87 | 67 | 87 | 47 | 80 | 67 | 93 | 80 | 80 | 94 | 89 | 56 |
| CFP w/o past | 93 | 67 | 87 | 87 | 93 | 60 | 93 | 33 | 20 | 94 | 22 | 11 |
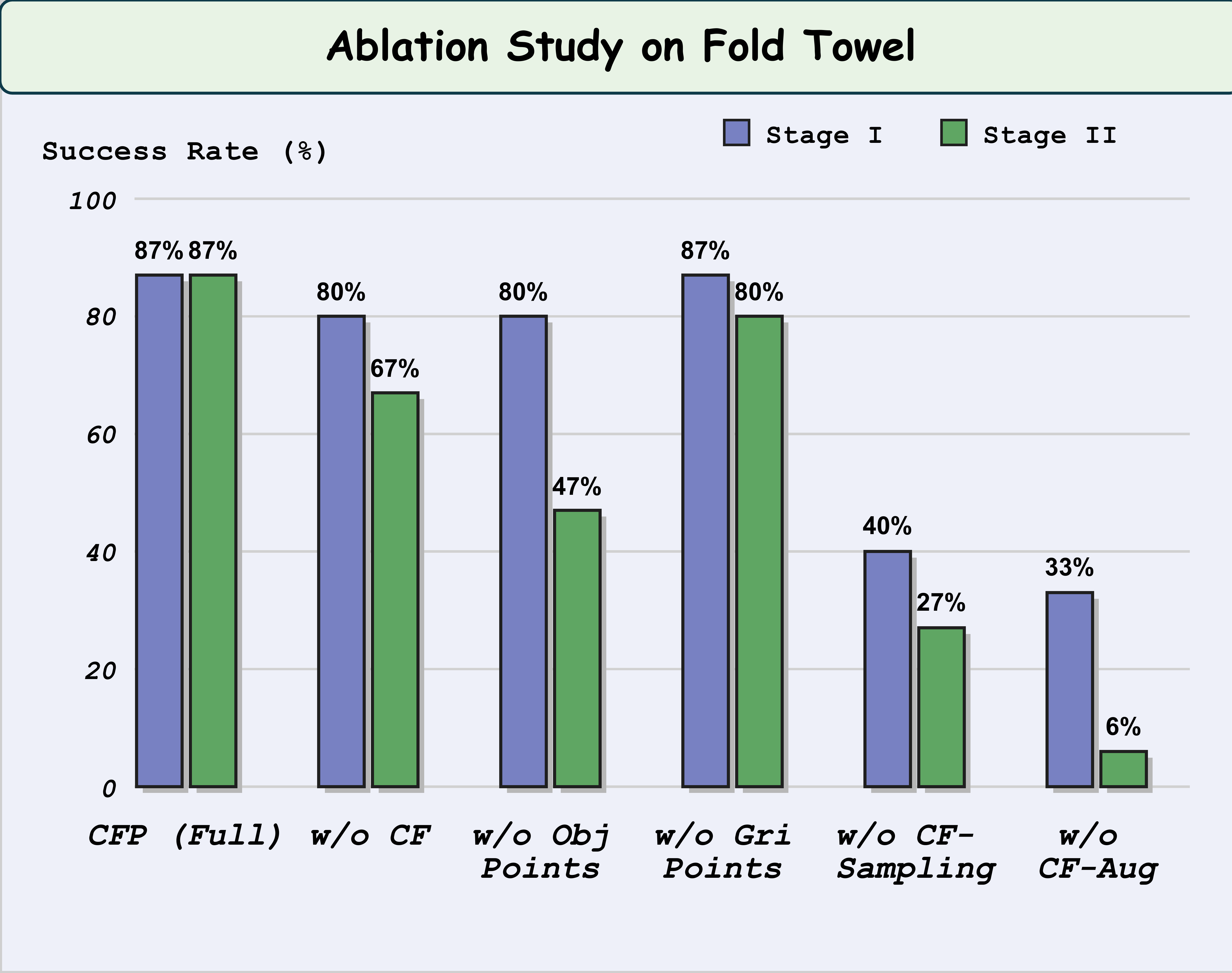
| CFP (ours) | 93 | 80 | 87 | 87 | 87 | 80 | 93 | 93 | 93 | 94 | 94 | 61 |
If you find this work useful, please consider citing:
@inproceedings{lin2026chronoflowpolicy,
title={ChronoFlow-Policy: Unifying Past-Current-Future Interaction Flow in Visuomotor Policy Learning},
author={Lin, Bokai and Xu, Yifu and Zhan, Xinyu and Fang, Hongjie and Tian, Jialin and Zhang, Fu-Cheng and Li, Yong-Lu and Lu, Cewu and Yang, Lixin},
booktitle={European Conference on Computer Vision (ECCV)},
year={2026}
}